ChronoLog 1.0.0 is now available! Download now for the latest features and improvements. For more information, visit the release blog post.
![]()
Chronolog: A High-Performance Storage Infrastructure for Activity and Log Workloads
HPC applications generate more data than storage systems can handle, and it is becoming increasingly important to store activity (log) data generated by people and applications. ChronoLog is a hierarchical, distributed log store that leverages physical time to achieve log ordering and reduce contention while utilizing storage tiers to elastically scale the log capacity.
Background
-
Modern application domains in science and engineering, from astrophysics to web services and financial computations generate massive amounts of data at unprecedented rates (reaching up to 7 TB/s).
-
The promise of future data utility and the low cost of data storage caused by recent hardware innovations (less than $0.02/GB) is driving this data explosion resulting in widespread data hoarding from researchers and engineers.
This trend stresses existing storage systems past their capability and exceeds the capacity of even the largest computing systems, and it is becoming increasingly important to store and process activity (log) data generated by people and applications. Including:
- Scientific Applications
- Internet Companies
- Financial Applications
- Microservices and Containers
- IoT
- Task-based Computing
Distributed log stores require:
- Total Ordering
- High Concurrency and Parallelism
- Capacity Scaling
Synopsis
This project will design and implement ChronoLog, a distributed and tiered shared log storage ecosystem. ChronoLog uses physical time to distribute log entries while providing total log ordering. It also utilizes multiple storage tiers to elastically scale the log capacity (i.e., auto-tiering). ChronoLog will serve as a foundation for developing scalable new plugins, including a SQL-like query engine for log data, a streaming processor leveraging the time-based data distribution, a log-based key-value store, and a log-based TensorFlow module.
Workloads & Applications
Modern applications spanning from Edge to High Performance Computing (HPC) systems, produce and process log data and create a plethora of workload characteristics that rely on a common storage model:
The Distributed Shared Log:

Challenges
- Ensuring total ordering of log data in a distributed environment is expensive
- Single point of contention (tail of the log)
- High cost of synchronization
- Centralized sequencers
- Efficiently scale log capacity
- Time- or space-based data retention policies
- Add servers offline and rebalance cluster
- Highly concurrent log operations by multiple clients
- Single-writer-multiple-readers (SWMR) data access model
- Limited operation concurrency
- I/O parallelism
- Application-centric implicit parallel model (e.g., consumer groups)
- Partial data retrieval (log querying)
- Expensive auxiliary indices
- Metadata look-ups
- Client-side epochs
| Features | Bookkeeper Kafka/DLog | Corfu SloG/ZLog | ChronoLog |
|---|---|---|---|
| Locating the log-tail | MDM lookup (locking) | Sequencer (locking) | MDM lookup (lock-free) |
| I/O isolation | Yes | No | Yes |
| I/O parallelism (readers-to-servers) | 1-to-1 | 1-to-N | M-to-N (always) |
| Storage elasticity (scaling capacity) | Only horizontal | No | Vertical and horizontal |
| Log hot zones | Yes (active ledger) | No | No |
| Log capacity | Data retention | Limited by # of SSDs | Infinite (auto-tiering) |
| Operation parallelism | Only Read (implicit) | Write/Read | Write/Read |
| Granularity of data distribution | Closed Ledgers (log-partition) | SSD page (set of entries) | Event (per entry) |
| Log total ordering | No (only on partitions) | Yes (eventually) | Yes |
| Log entry visibility | Immediate | End of epoch | Immediate |
| Storage overhead per entry | Yes (2x) | No | No |
| Tiered storage | No | No | Yes |
Key Insights & Project Impact
Research Contributions
- How physical time can be used to distribute and order log data without the need for explicit synchronizations or centralized sequencing offering a high-performance and scalable shared log store with the ability to support efficient range data retrieval.
- How multi-tiered storage can be used to scale the capacity of a log and offer tunable data access parallelism while maintaining I/O isolation and a highly concurrent access model supporting multiple-writers-multiple-readers (MWMR).
- How elastic storage semantics and dynamic resource provisioning can be used to achieve an efficient matching between I/O production and consumption rates of conflicting workloads under a single system.
Software Contributions
ChronoLog will create a future-proof storage infrastructure targeting large-scale systems and applications.
- The ChronoLog Core Library
- An in-memory lock-free distributed journal with the ability to persist data on flash storage to enable a fast distributed caching layer
- A new high-performance data streaming service specifically, but not limited, for HPC systems that uses MPI for job distribution and RPC over RDMA (or over RoCE) for communication
- A set of high-level interfaces for I/O
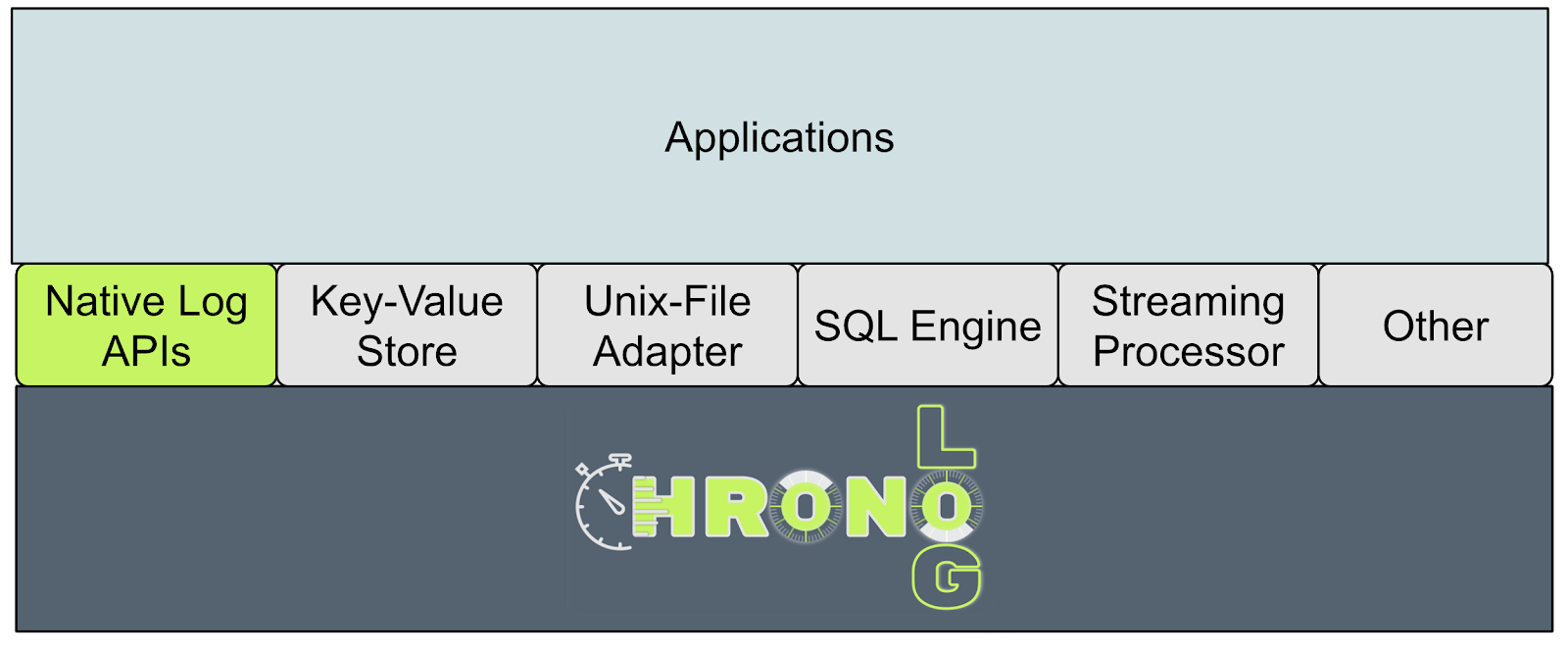
Design Requirements
Architecture
ChronoLog is a new class of a distributed shared log store that will leverage physical time for achieving total ordering of log entries and will utilize multiple storage tiers to distribute a log both horizontally and vertically (a model we call 3D data distribution).
Data Model & API
Design Details

- The ChronoVisor
- Handles client connections
- Holds chronicle metadata information
- Acts as the global clock enforcing time synchronization between all server nodes
- Deployed on its own server node (usually a head node)
- The ChronoKeeper
- Serves all tail operations such as record() (append) and playback() (tail-read)
- Stores incoming events in a distributed journal
- Deployed on all or a subset of compute nodes that are equipped with a fast flash storage
- The ChronoStore
- Manages both intermediate storage resources (e.g., burst buffers or data staging resources) and the storage servers
- Has the ability to grow or shrink its resources offering an elastic solution that can react to the I/O traffic
- Organized into the ChronoGrapher and ChronoPlayer, which are responsible for writes and reads, respectively
- The ChronoGrapher
- Continuously ingests events from the ChronoKeeper
- Uses a real-time data streaming approach to persist events to lower tiers of the hierarchy
- The ChronoPlayer
- Serves historical reads in the form of replay() (catch-up read) calls
Features & Operations

Log Auto-Tiering
To provide chronicle capacity scaling, ChronoLog moves data down to the next larger but slower tiers automatically. To achieve this, the ChronoGrapher offers a very fast distributed data flushing solution, that can match the event production rate, by offering:
- Real-time continuous data flushing
- Tunable parallelism via resource elasticity
- Storage device-aware random access
- A decoupled server-pull, instead of a client-push, eviction model

ChronoGrapher runs a data streaming job with three major steps represented as a DAG: event collection, story building, and story writing. Each node in the DAG is dynamic and elastic based on the incoming traffic estimated by the number of events and total size of data.
Log Querying & Range Retrieval
The ChronoPlayer is responsible for executing historical read operations.

- Initialized by the ChronoVisor upon system initialization
- Accesses data from all available tiers
- Implemented by a data streaming approach
- Real-time, decoupled, and elastic architecture
Evaluation Results
Publications
Authors | Title | Venue | Type | Date | Links |
|---|---|---|---|---|---|
| , , , , | Stimulus: Accelerate Data Management for Scientific AI applications in HPC | The 22nd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID'22), May 16-19, 2022 | Conference | May, 2022 | |
| , , , , , , , | HFlow: A Dynamic and Elastic Multi-Layered Data Forwarder | The 2021 IEEE International Conference on Cluster Computing (CLUSTER'21), September 7-10, 2021 | Conference | September, 2021 | |
| , , , , , , , | Apollo: An ML-assisted Real-Time Storage Resource Observer | The 30th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC'21), June 21-25, 2021 | Conference | June, 2021 | |
| , , , , | DLIO: A Data-Centric Benchmark for Scientific Deep Learning Applications | The 2021 IEEE/ACM International Symposium in Cluster, Cloud, and Internet Computing (CCGrid'21), May 17 - 20, 2021 Best paper award | Conference | May, 2021 | |
| , , | HReplica: A Dynamic Data Replication Engine with Adaptive Compression for Multi-Tiered Storage | The 2020 IEEE International Conference on Big Data (Big Data'20), December 10-13, 2020 | Conference | December, 2020 | |
| , , | A Dynamic Multi-Tiered Storage System for Extreme Scale Computing | The International Conference for High Performance Computing, Networking, Storage and Analysis (SC'20) | Poster | November, 2020 | |
| , , , | HCL: Distributing Parallel Data Structures in Extreme Scales | IEEE International Conference on Cluster Computing (CLUSTER'20), Sept. 14-17, 2020 | Conference | September, 2020 | |
| , , , | HCompress: Hierarchical Data Compression for Multi-Tiered Storage Environments | IEEE International Parallel and Distributed Processing Symposium (IPDPS'20), May 18-22, 2020 | Conference | May, 2020 | |
| , , | HFetch: Hierarchical Data Prefetching for Scientific Workflows in Multi-Tiered Storage Environments | IEEE International Parallel and Distributed Processing Symposium (IPDPS'20), May 18-22, 2020 | Conference | May, 2020 | |
| , , | I/O Acceleration via Multi-Tiered Data Buffering and Prefetching | Journal of Computer Science and Technology (JCST'20), vol 35. no 1. pp 92-120 | Journal | January, 2020 | |
| , , | HFetch: Hierarchical Data Prefetching in Multi-Tiered Storage Environments | The International Conference for High Performance Computing, Networking, Storage and Analysis (SC'19) Best Poster Nominee, Ph.D Forum | Poster | November, 2019 | |
| , , , | LABIOS: A Distributed Label-Based I/O System | The 28th International Symposium on High-Performance Parallel and Distributed Computing (HPDC'19), Phoenix, USA 2019. pp. 13-24. Karsten Schwan Best Paper Award | Conference | June, 2019 | |
| , , | An Intelligent, Adaptive, and Flexible Data Compression Framework | IEEE/ACM International Symposium in Cluster, Cloud, and Grid Computing (CCGrid'19), Larnaca, Cyprus2019. pp. 82-91. | Conference | May, 2019 | |
| , , , | Vidya: Performing Code-Block I/O Characterization for Data Access Optimization | The IEEE International Conference on High Performance Computing, Data, and Analytics 2018 (HiPC'18), Bengaluru, India2018. pp. 255-264. | Conference | December, 2018 | |
| , , , | Harmonia: An Interference-Aware Dynamic I/O Scheduler for Shared Non-Volatile Burst Buffers | The IEEE International Conference on Cluster Computing 2018 (Cluster'18), Belfast, UK2018. pp. 290-301. | Conference | September, 2018 | |
| , , | Hermes: A Heterogeneous-Aware Multi-Tiered Distributed I/O Buffering System | The 27th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC), Tempe, AZ, USA, 2018. pp. 219-230 | Conference | June, 2018 |
Members
Collaborators
Sponsor
National Science Foundation (NSF CSSI-2104013)
