![]()
Hermes: Extending the HDF Library to Support Intelligent I/O Buffering for Deep Memory and Storage Hierarchy System
To reduce the I/O bottleneck, complex storage hierarchies have been introduced. However, managing this complexity should not be left to application developers. Hermes is a middeware library that automatically manages buffering in heterogeneous storage environments.
Hermes 1.2.0 is now available! Download now for the latest features and improvements.
Background
Today's multi-tiered environments demonstrate:
- Complex data placement among the tiers of a deep memory and storage hierarchy
- Lack of automated data movement between tiers, is now left to the users
- Lack of intelligent data placement in the DMSH
- Independent management of each tier of the DMSH
- Lack of expertise from the user
- Lack of existing software for managing tiers of heterogeneous buffers
- Lack of native buffering support in HDF5
Deep memory and storage hierarchy (DMSH) systems requires:
- Efficient and transparent data movement through the hierarchy
- New data placement algorithms
- Effective memory and metadata management
- An efficient communication fabric
Synopsis
Modern high performance computing (HPC) applications generate massive amounts of data. However, the performance improvement of disk based storage systems has been much slower than that of memory, creating a significant Input/Output (I/O) performance gap. To reduce the performance gap, storage subsystems are under extensive changes, adopting new technologies and adding more layers into the memory/storage hierarchy. With a deeper memory hierarchy, the data movement complexity of memory systems is increased significantly, making it harder to utilize the potential of the deep memory and storage hierarchy (DMSH) design.
As we move towards the exascale era, I/O bottleneck is a must to solve performance bottleneck facing the HPC community. DMSHs with multiple levels of memory/storage layers offer a feasible solution but are very complex to use effectively. Ideally, the presence of multiple layers of storage should be transparent to applications without having to sacrifice I/O performance. There is a need to enhance and extend current software systems to support data access and movement transparently and effectively under DMSHs.
Hierarchical Data Format (HDF) technologies are a set of current I/O solutions addressing the problems in organizing, accessing, analyzing, and preserving data. HDF5 library is widely popular within the scientific community. Among the high level I/O libraries used in DOE labs, HDF5 is the undeniable leader with 99% of the share. HDF5 addresses the I/O bottleneck by hiding the complexity of performing coordinated I/O to single, shared files, and by encapsulating general purpose optimizations. While HDF technologies, like other existing I/O middleware, are not designed to support DMSHs, its wide popularity and its middleware nature make HDF5 an ideal candidate to enable, manage, and supervise I/O buffering under DMSHs.
This project proposes the development of Hermes, a heterogeneous aware, multi-tiered, dynamic, and distributed I/O buffering system that will significantly accelerate I/O performance.
This project proposes to extend HDF technologies with the Hermes design. Hermes is new, and the enhancement of HDF5 is new. We believe that the combination of DMSH I/O buffering and HDF technologies is a reachable practical solution that can efficiently support scientific discovery.
Why Hermes?
Hermes will advance HDF5 core technology by developing new buffering algorithms and mechanisms to support:
- Vertical and Horizontal Buffering in DMSHs
- Here vertical means access data to/from different levels locally and horizontal means spread/gather data across remote compute nodes
- Selective Buffering via HDF5
- Here selective means some memory layer, e.g. NVMe, only for selected data
- Dynamic Buffering via Online System Profiling
- The buffering schema can be changed dynamically based on messaging traffic
- Adaptive Buffering via Reinforcement Learning
- By learning the application's access pattern, we can adapt prefetching algorithms and cache replacement policies at runtime.
A new, multi-tiered, distributed buffering platform that is:
- Hierarchical
- Enables, manages, and supervises I/O operations in the Deep Memory and Storage Hierarchy (DMSH)
- Dynamic
- Offers selective and dynamic layered data placement
- Modular
- Is modular, extensible, and performance-oriented
- Flexible
- Supports a wide variety of applications (scientific, BigData, etc)

Contributions
Architecture
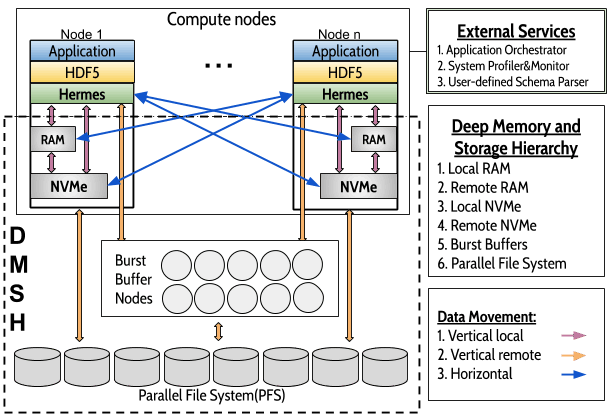
- Hermes machine model
- Large amount of RAM
- Local NVMe and/or SSD device
- Shared Burst Buffers
- Remote disk-based PFS
- Fully distributed
- Fully scalable deployment on distributed clusters, consisting of node/local end remote shared storage layers
- Two data paths
- Vertical ->within node
- Horizontal ->across nodes
- Hierarchy based on
- Access Latency
- Data Throughput
- Capacity
Node Design
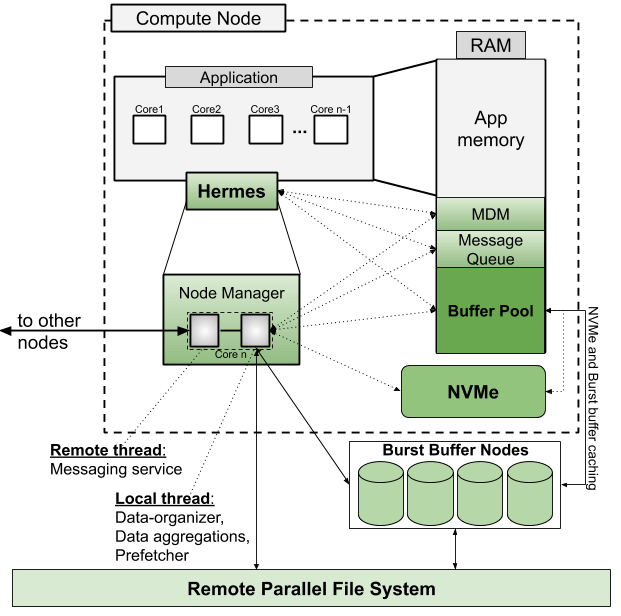
- Dedicated core for Hermes
- RDMA-capable communication
- Can also be deployed in I/O Forwarding Layer
- Multithreaded Node Manager
Components
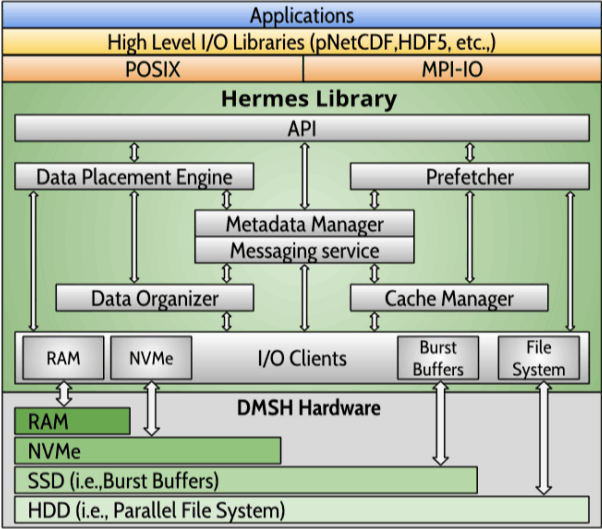
- Middle-ware library written in C++: Link with applications (i.e., re-compile or LD_PRELOAD) and Wrap-around I/O calls
- Modular, extensible, performance-oriented
- Will support: POSIX, HDF5 and MPI-IO
- Hinting mechanism to pass user's operations
Objectives
- Being application- and system-aware
- Maximizing productivity
- Increasing resource utilization
- Abstracting data movement
- Maximizing performance
- Supporting a wide range of scientific applications and domains
Design Implications

Evaluation Results
Hermes Library Evaluation
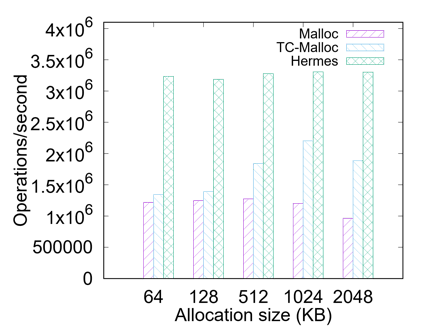
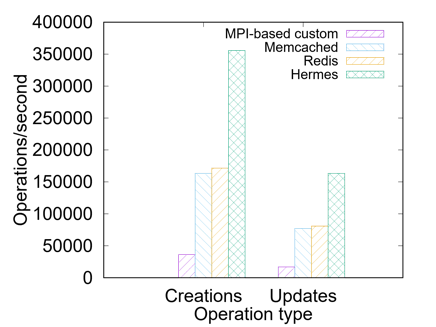
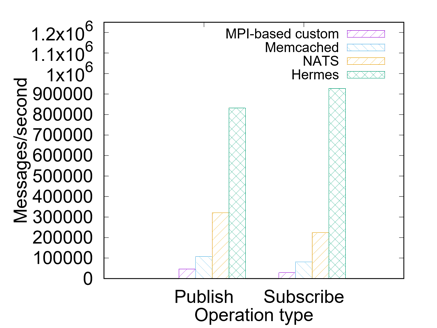
Workload Evaluation
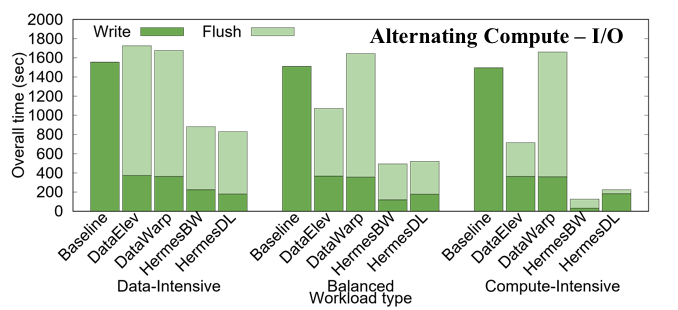
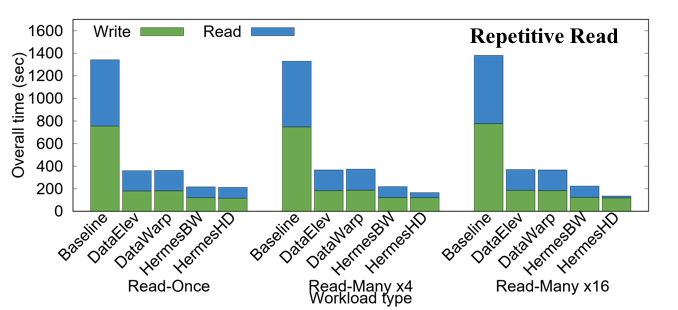
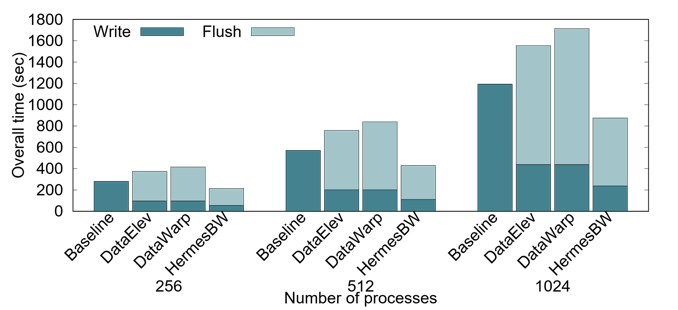
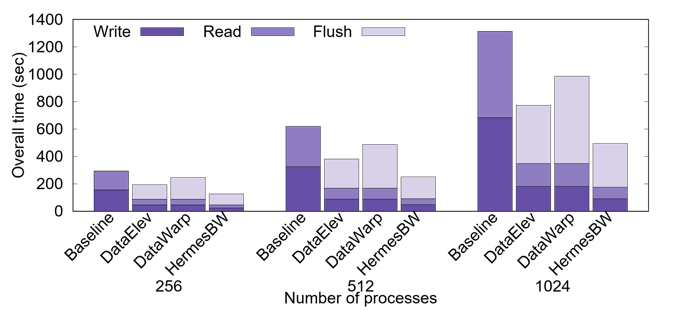
Webinars

Hermes Beta Release

Hermes Update - HDF Group

Hermes Buffer Organizer - HDF Group
Publications
Authors | Title | Venue | Type | Date | Links |
|---|---|---|---|---|---|
| , , , , | Stimulus: Accelerate Data Management for Scientific AI applications in HPC | The 22nd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID'22), May 16-19, 2022 | Conference | May, 2022 | |
| , , , , , , , | HFlow: A Dynamic and Elastic Multi-Layered Data Forwarder | The 2021 IEEE International Conference on Cluster Computing (CLUSTER'21), September 7-10, 2021 | Conference | September, 2021 | |
| , , , , , , , | Apollo: An ML-assisted Real-Time Storage Resource Observer | The 30th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC'21), June 21-25, 2021 | Conference | June, 2021 | |
| , , , , | DLIO: A Data-Centric Benchmark for Scientific Deep Learning Applications | The 2021 IEEE/ACM International Symposium in Cluster, Cloud, and Internet Computing (CCGrid'21), May 17 - 20, 2021 Best paper award | Conference | May, 2021 | |
| , , | HReplica: A Dynamic Data Replication Engine with Adaptive Compression for Multi-Tiered Storage | The 2020 IEEE International Conference on Big Data (Big Data'20), December 10-13, 2020 | Conference | December, 2020 | |
| , , | A Dynamic Multi-Tiered Storage System for Extreme Scale Computing | The International Conference for High Performance Computing, Networking, Storage and Analysis (SC'20) | Poster | November, 2020 | |
| , , , | HCL: Distributing Parallel Data Structures in Extreme Scales | IEEE International Conference on Cluster Computing (CLUSTER'20), Sept. 14-17, 2020 | Conference | September, 2020 | |
| , , , | HCompress: Hierarchical Data Compression for Multi-Tiered Storage Environments | IEEE International Parallel and Distributed Processing Symposium (IPDPS'20), May 18-22, 2020 | Conference | May, 2020 | |
| , , | HFetch: Hierarchical Data Prefetching for Scientific Workflows in Multi-Tiered Storage Environments | IEEE International Parallel and Distributed Processing Symposium (IPDPS'20), May 18-22, 2020 | Conference | May, 2020 | |
| , , | I/O Acceleration via Multi-Tiered Data Buffering and Prefetching | Journal of Computer Science and Technology (JCST'20), vol 35. no 1. pp 92-120 | Journal | January, 2020 | |
| , , | HFetch: Hierarchical Data Prefetching in Multi-Tiered Storage Environments | The International Conference for High Performance Computing, Networking, Storage and Analysis (SC'19) Best Poster Nominee, Ph.D Forum | Poster | November, 2019 | |
| , , , | LABIOS: A Distributed Label-Based I/O System | The 28th International Symposium on High-Performance Parallel and Distributed Computing (HPDC'19), Phoenix, USA 2019. pp. 13-24. Karsten Schwan Best Paper Award | Conference | June, 2019 | |
| , , | An Intelligent, Adaptive, and Flexible Data Compression Framework | IEEE/ACM International Symposium in Cluster, Cloud, and Grid Computing (CCGrid'19), Larnaca, Cyprus2019. pp. 82-91. | Conference | May, 2019 | |
| , , , | Vidya: Performing Code-Block I/O Characterization for Data Access Optimization | The IEEE International Conference on High Performance Computing, Data, and Analytics 2018 (HiPC'18), Bengaluru, India2018. pp. 255-264. | Conference | December, 2018 | |
| , , , | Harmonia: An Interference-Aware Dynamic I/O Scheduler for Shared Non-Volatile Burst Buffers | The IEEE International Conference on Cluster Computing 2018 (Cluster'18), Belfast, UK2018. pp. 290-301. | Conference | September, 2018 | |
| , , | Hermes: A Heterogeneous-Aware Multi-Tiered Distributed I/O Buffering System | The 27th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC), Tempe, AZ, USA, 2018. pp. 219-230 | Conference | June, 2018 |
Members







Sponsor
National Science Foundation
(NSF OCI-1835764)

FAQ
Q: The DPE policies rely on the fact that users know the behavior of their application in advance which can be a bold assumption, right?
A: That is true. We suggest using profiling tools beforehand to learn about the application’s behavior and tune Hermes. Default policy works great.
Q: How does Hermes integrate to modern HPC environments?
A: As of now, applications link to Hermes (re-compile or dynamic linking). We envision a system scheduler that also incorporates buffering resources.
Q: How are Hermes’ policies applied in multi-user environments?
A: Hermes’ Application Orchestrator was designed for multi-tenant environments. This work is described in Vidya: Performing Code-Block I/O Characterization for Data Access Optimization.
Q: What is the impact of the asynchronous data reorganization?
A: It can be severe but in scenarios where there is some computation in between I/O then it can work nicely to our advantage.
Q: What is the metadata size?
A: In our evaluation, for 1 million user files, the metadata created were 1.1GB.
Q: How to balance the data distribution across different compute nodes especially when the I/O load is imbalanced across nodes?
A: Hermes’ System Profiler provides the current status of the system (i.e., remaining capacity, etc) and DPE is aware of this before it places data in the DMSH.