![]()
DaYu: Optimizing Workflow Performance by Elucidating Semantic Data Flow
Distributed scientific workflows nowadays face challenges in data movement through storage systems. DaYu employs careful runtime measurement, maps domain semantics to low-level I/O operations, and utilizes effective visualization and analysis of semantic data flows to understand how semantic datasets move through storage.
Introduction
High-Performance Computing (HPC) workflows are evolving with increasing data intensity. These workflows are growing in complexity, featuring multiple stages encompassing simulation, analysis, and AI applications with diverse data demands. Data transfer between HPC tasks currently relies on shared storage layers like Parallel File System (PFS) and Burst Buffer, which can suffer from slow access and I/O contention.
Enhancing data movement within workflows poses a significant challenge. Strategic task scheduling, data caching, and staging have emerged as effective means to boost I/O performance by reducing computation wait times. With more I/O expertise, one can also utilize and fine-tune various I/O libraries, middleware, and file system configurations. The tuning often requires iterative testing and are limited to specific workload, whille other workloads still experiencing high latency with shared storage.
Understanding I/O behavior is imperative when deciding on the correct strategies to enhance data access. Details about data access within workflow tasks can effectively guide improvements in I/O and system configuration. Existing application I/O profiling tools lack the ability to provide analyze of data access behavior across tasks in a workflow and capture semantic information related to its low-level I/O requests. Such tools would be valuable for providing more straightforward insights into data access patterns across multiple tasks. By filling this gap, we can develop better methods for managing data movement and optimizing the overall workflow.
In this work, we unveil a fresh workflow optimization perspective with
- careful runtime measurement of data access metrics,
- recovering the mapping of domain semantics to low-level I/O operations, and
- effective visualization and analysis of semantic data flows for the complete workflow.
Background

HDF5 File Structure Overview
HDF5 is a widely used storage format and I/O libraries in scientific applications
- Hierarchical structure of groups, datasets, and attributes
- Allows enriched metadata that describes different data characteristics
- Extensive API enabling tracking of its high-level data object and the low-level I/O
Approach
The project's major challenges include mapping data semantics to I/O access, tracking data flow across tasks, and visualizing coordination and time. Our approach consists of three steps:

Case Study I: Storm Tracking Workflow
PyFLEXTRKR uses a flexible atmospheric feature tracking software package for weather research and forecast datasets.

Six-Stages Pipeline PyFLEXTRKR Workflow.
Observations
- Inter-task Data Reuse: task 2, 4, and 6 uses files produced by the first task.
- Time-dependents inputs: some input files are required at different time point.
- Data None-Used: file produced by task 4 is not used by any later task.
Opportunities
- Tasks that use common datasets can be scheduled on the same resource.
- Input can be stage-in at different time points of the workflow.
- not used by later tasks can be immediately offloaded to free up memory.
Case Study II: DeepDriveMD Workflow
DeepDriveMD (DDMD) is a deep learning-driven molecular dynamics simulations workflow for protein folding.
Workflow Task-File DAG
Four-Stages Pipeline Workflow (simulation, aggregate, train, and inference).
Observation: No data dependencies between Train and Inference tasks,
as we can see that both of them reads input aggregated.h5, and output different
sets of files that are not used by each other.
Opportunity: Inference and Train tasks can be parallelized
without violating data dependency correctness.
Semantic DAG 1
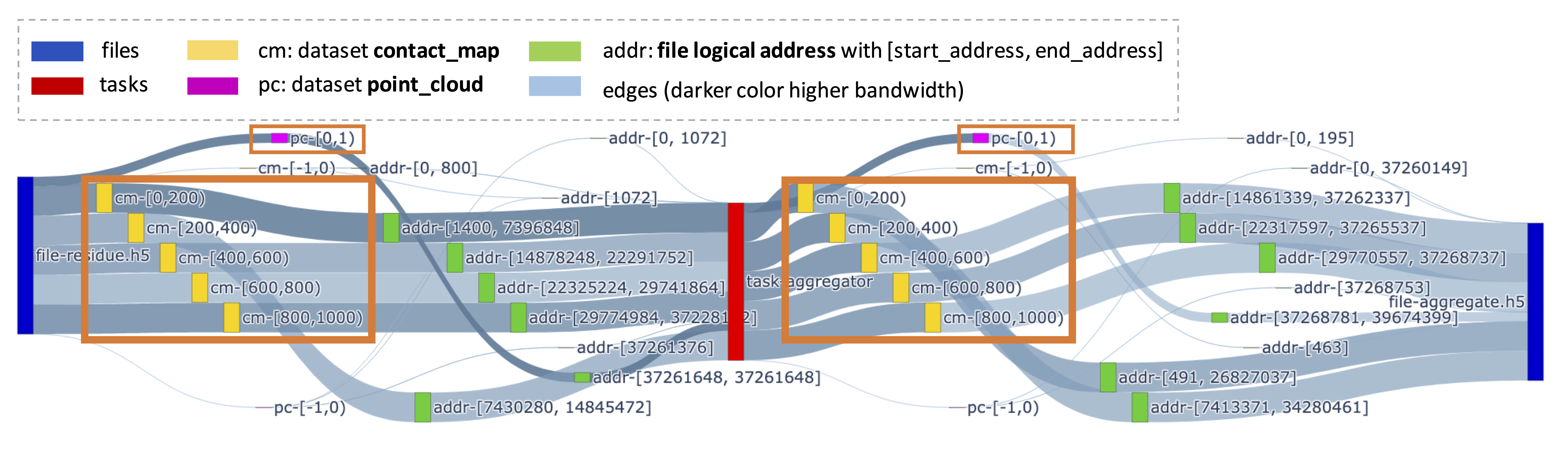
Aggregate Stage Close-Up Semantic DAG with Two Datasets.
Observation: The Aggregate task alters the data layout of large datasets without changing the content.
Over 95% of the data volume is from the contact_map dataset, while only small amount is from the
point_cloud dataset.
Opportunity: Removing the Aggregate task does not compromise the correctness of the program.
We have Train and Inference task reading input directly from simulation, this can reduce unnecessary
data manipulation and movement and improve data access parallelism.
Semantic DAG 2

DDMD Train Stage Read File I/O Performance Detail.
Observation: The Train task is not accessing all the datasets present in the aggregated.h5 file.
In fact, it is not using the largest datasets which takes up 95% of the file space (from previous observation).
Opportunities
- Removing the
Aggregatetask can minimize unnecessary data transfers. - Caching a subset of the
aggregated.h5file does not violate task-data dependencies.
Conclusion
Nowadays in HPC applications, there is a lack of tools to understand data flow between tasks in a workflow. This study introduced Semantic DAGs, an enriched version of traditional DAGs. Precise measurements allowed us to reconstruct mappings between tasks and meaningful data objects down to I/O with file addresses. With visualization of task-to-data mapping and extracted performance statistics, we can gain new insight into workflow optimization opportunities.
Our future work will focus on enhancing the analysis method and creating a generalized approach for customized data placement in workflows. We aim to achieve this through I/O buffering middleware and apply our analysis for effective I/O system tuning to meet workload requirements.
Members
- Meng Tang
- PhD Student @ GRC
- Illinois Institute of Technology
- Contact
- Dr. Nathan R. Tallent
- Co-Principal Investigator
- Pacific Northwest National Laboratory (PNNL)
- Contact
- Dr. Anthony Kougkas
- Co-Principal Investigator
- Illinois Institute of Technology
- Contact
- Dr. Xian-He Sun
- Principal Investigator
- Illinois Institute of Technology
- Contact
Sponsor

This research is supported by the U.S. Department of Energy (DOE) through the Office of Advanced Scientific Computing Research's "Orchestration for Distributed & Data-Intensive Scientific Exploration."

This research is also based upon work supported by the National Science Foundation under Grant no. NSF CSSI-2104013.