Optimization of Memory Architectures: A Foundation Approach
Background
The "memory wall" problem is a significant performance bottleneck in modern computer architectures, driven by an ever-widening disparity between CPU and memory speeds. Despite advancements over the past three decades—including multi-core and many-core designs, deep pipelining, and innovative caching techniques (such as multi-port, multi-banked, pipelined, and non-blocking caches)—the "memory wall" persists. If anything, the problem has intensified with the rise of data-intensive applications, which place additional demands on memory systems.
Concurrent Average Memory Access Time (C-AMAT) is a memory performance model that extends the traditional Average Memory Access Time (AMAT) to address the complexities of modern systems, where concurrent memory accesses are prevalent. Unlike AMAT, which assumes sequential memory access, C-AMAT integrates both data concurrency and locality into a single unified metric. This metric applies recursively across all layers of the memory hierarchy, making C-AMAT an invaluable tool for accurately modeling and optimizing memory systems in contemporary architectures.
This project aims to develop advanced memory-architecture performance-modeling and optimization frameworks that effectively capture the combined effects of data locality, data concurrency, and data access overlap. This work provides a foundation for future architecture designs that better balance CPU and memory capabilities, paving the way for more efficient and scalable systems in the data-driven era.
Project Contributions
1. Unified Mathematical Framework for Memory Access
A coherent mathematical framework was developed for a memory-centric view of data accesses, which enables a recursive definition of memory access latency and concurrency along the memory hierarchy, providing clearer insights into memory performance. The Concurrent Average Memory Access Time (C-AMAT) model was expanded to cover more general situations in hierarchical memory systems, accounting for splitting and merging at specific cache memory devices. Additionally, partitioning techniques were revisited to account for concurrent data access.
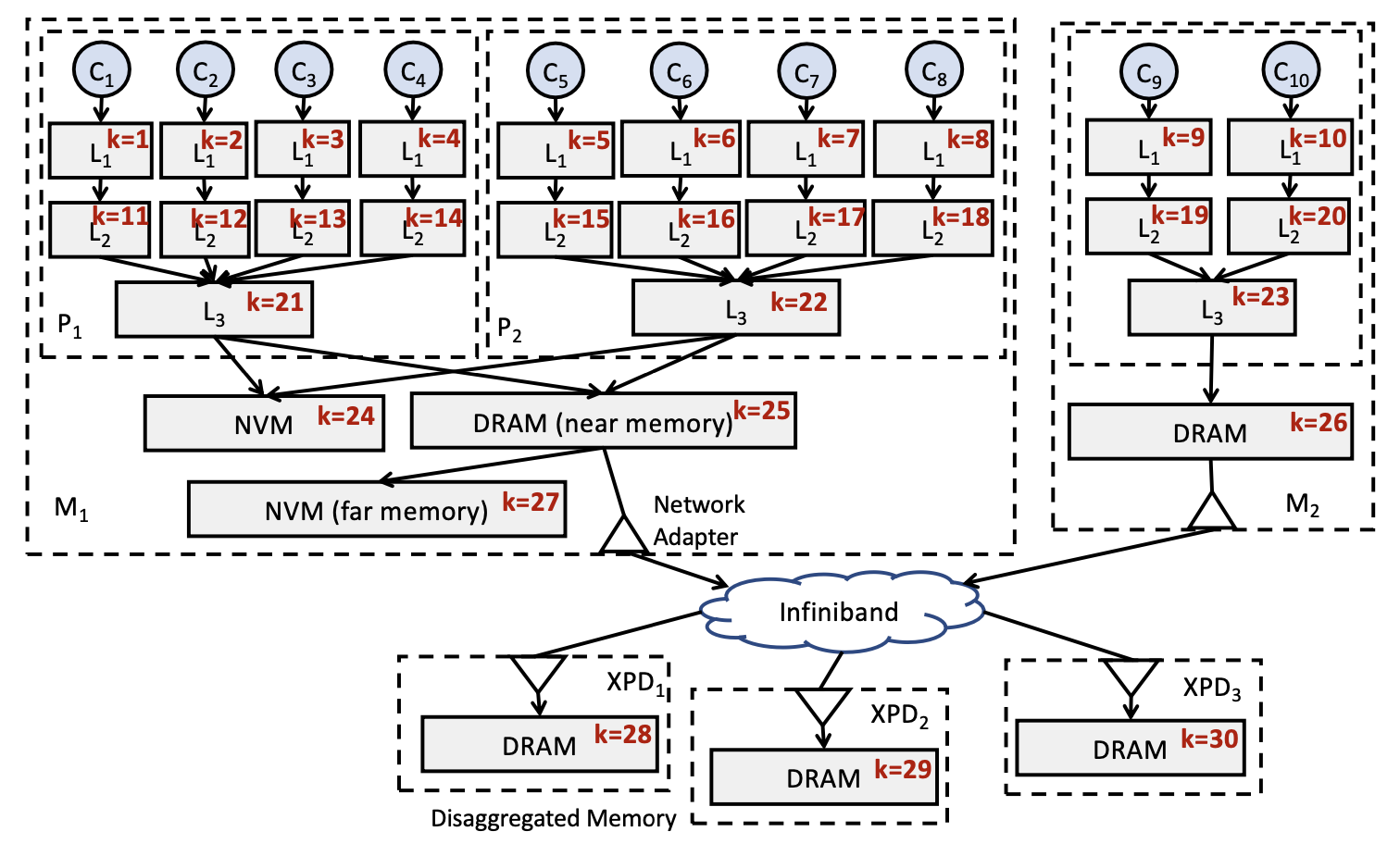
A Memory System Viewed as a Multi-tree.
2. Concurrency-Aware Performance Optimization Frameworks
- APAC Prefetch Framework: APAC is an adaptive prefetch framework that adjusts prefetch aggressiveness based on concurrent memory access patterns, optimizing both prefetch accuracy and coverage. In both single-core and multi-core environments, APAC demonstrates substantial performance improvements, with an average 17.3% IPC gain over state-of-the-art adaptive frameworks.
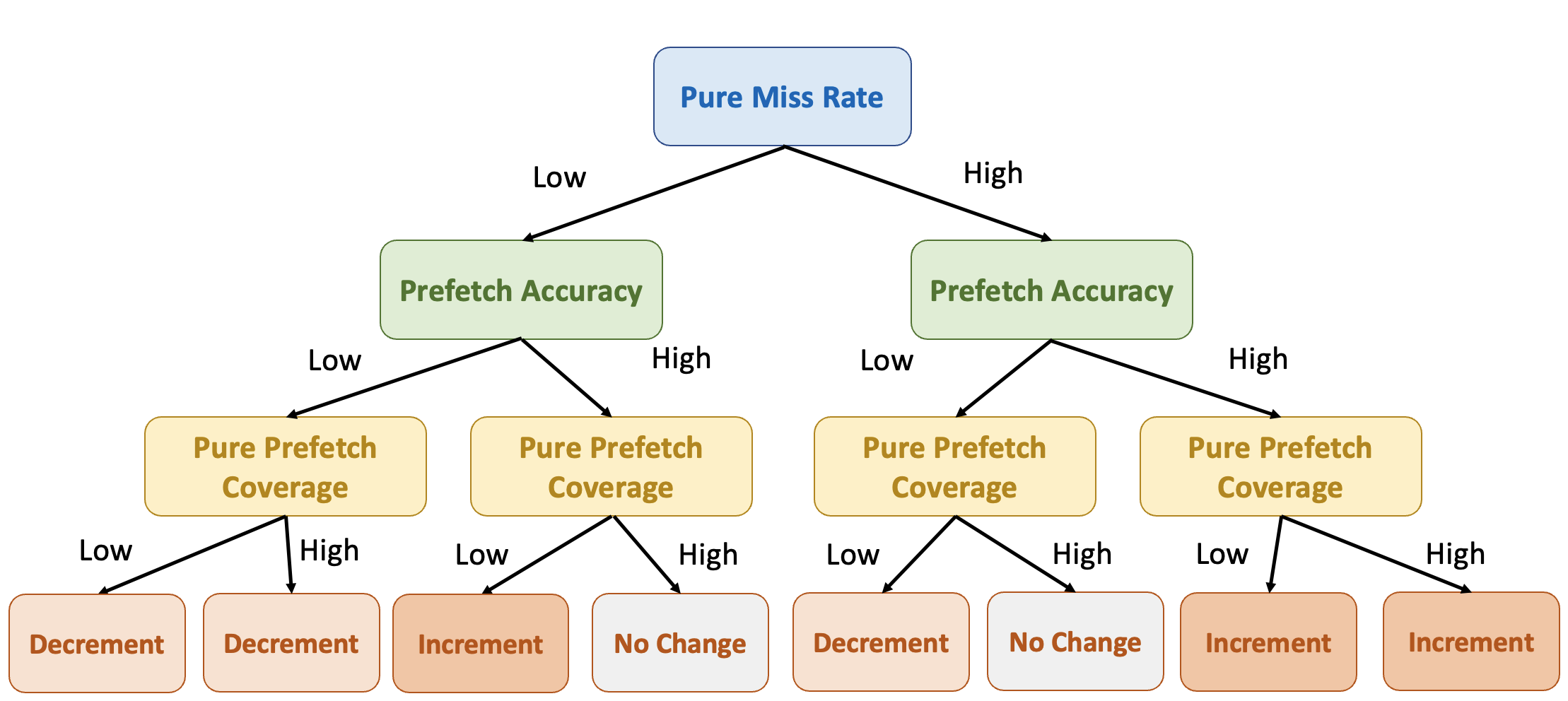
Adjust Prefetch Aggressiveness with Runtime Metrics.
- Premier Cache Partitioning Framework: Premier is a concurrency-aware cache partitioning framework that leverages the Pure Misses Per Kilo Instructions (PMPKI) metric to dynamically allocate cache capacity and mitigate interference. Premier offers adaptive insertion and dynamic capacity allocation to maximize cache efficiency. Premier outperforms traditional partitioning schemes, achieving a 15.45% performance improvement and a 10.91% fairness increase in 8-core systems, demonstrating its strength in managing shared LLC resources effectively.
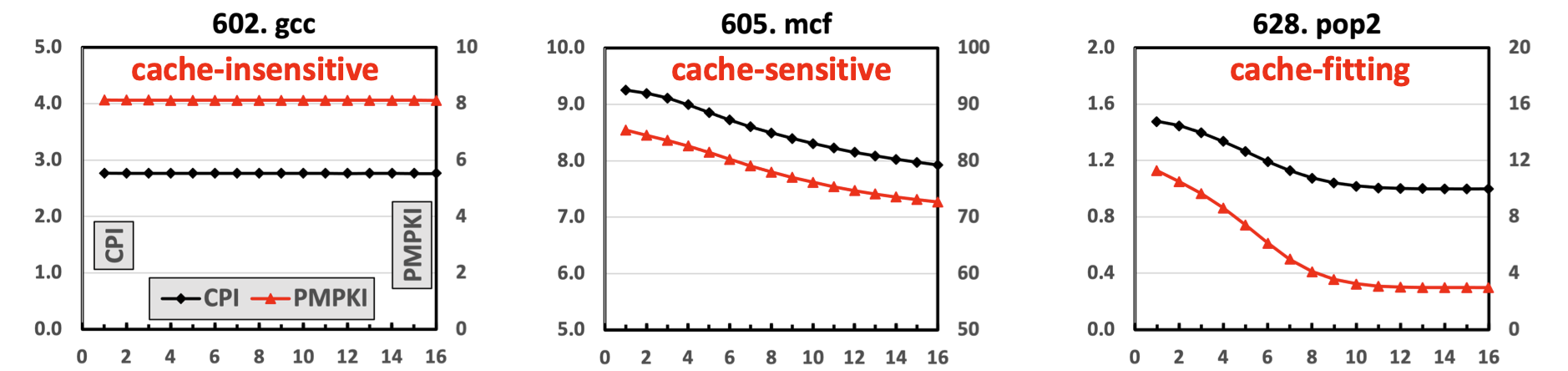
PMPKI and CPI for Varying Cache Sizes in SPEC Workloads.
- CARE Concurrency-Aware Cache Management: CARE introduces an innovative approach that goes beyond traditional locality-based management, utilizing the Pure Miss Contribution (PMC) metric to prioritize cache replacements. CARE dynamically adjusts cache management decisions, aligning cache behavior with varying workload demands for enhanced efficiency. CARE achieves substantial improvements over traditional LRU policies, with an average 10.3% IPC gain in 4-core systems and up to 17.1% IPC improvement in 16-core systems. These results demonstrate CARE's scalability and effectiveness in high-concurrency environments.
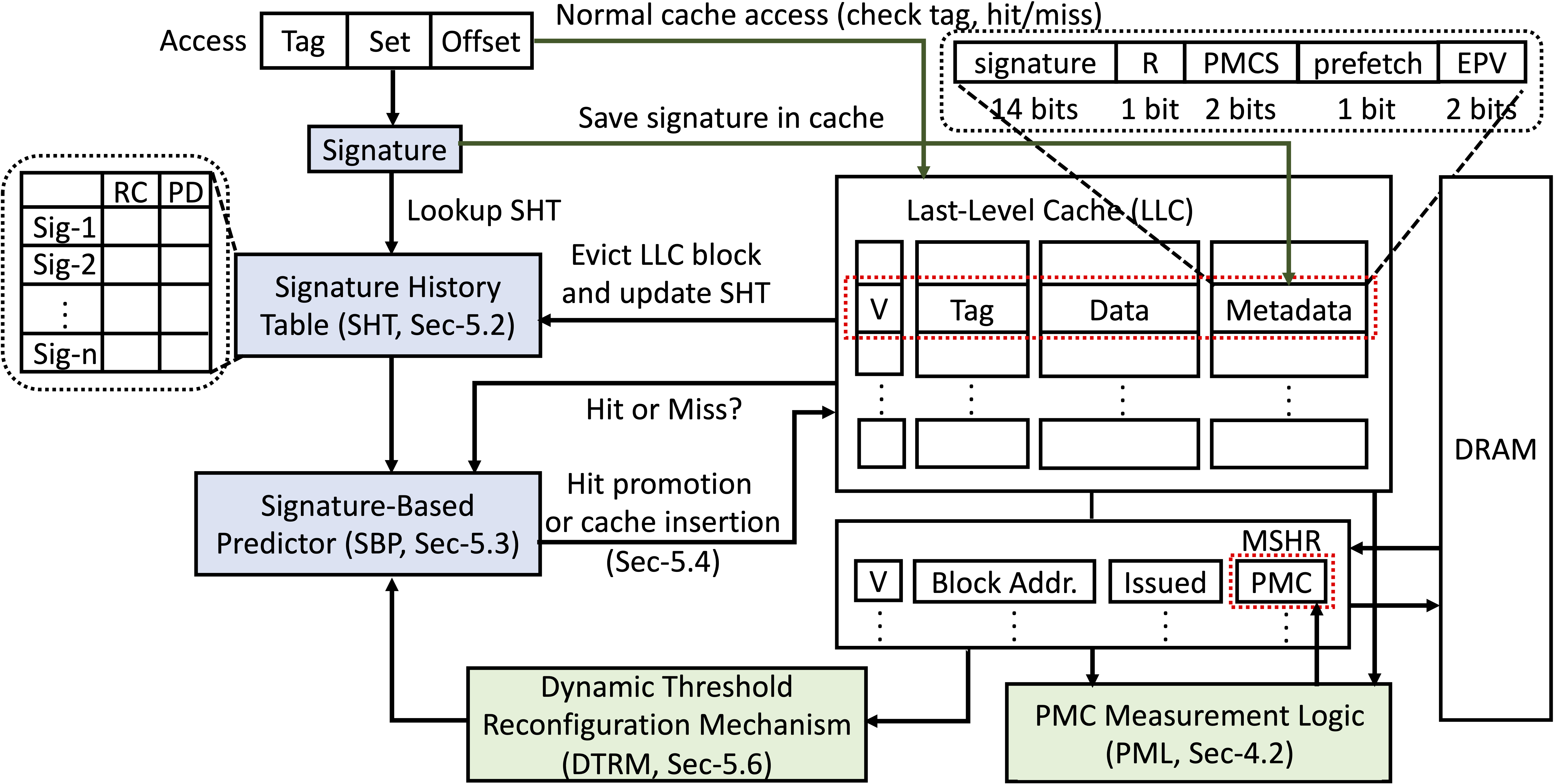
The Overview of the CARE Design.
- CHROME Holistic Cache Management: CHROME is an innovative cache management framework that leverages concurrency-aware, online reinforcement learning to optimize cache performance in dynamic environments. By continuously interacting with the processor and memory system, CHROME learns and adapts its cache management policy in real-time. This online reinforcement learning approach enables CHROME to perform effectively across diverse system configurations and fluctuating workloads. CHROME makes bypassing and replacement decisions based on multiple program features and system-level feedback, considering concurrency to enhance overall cache efficiency. Extensive evaluations show that CHROME consistently outperforms traditional cache management schemes, achieving a 13.7% performance improvement in 16-core systems, proving its potential for improving cache performance in data-intensive, scalable computing systems.
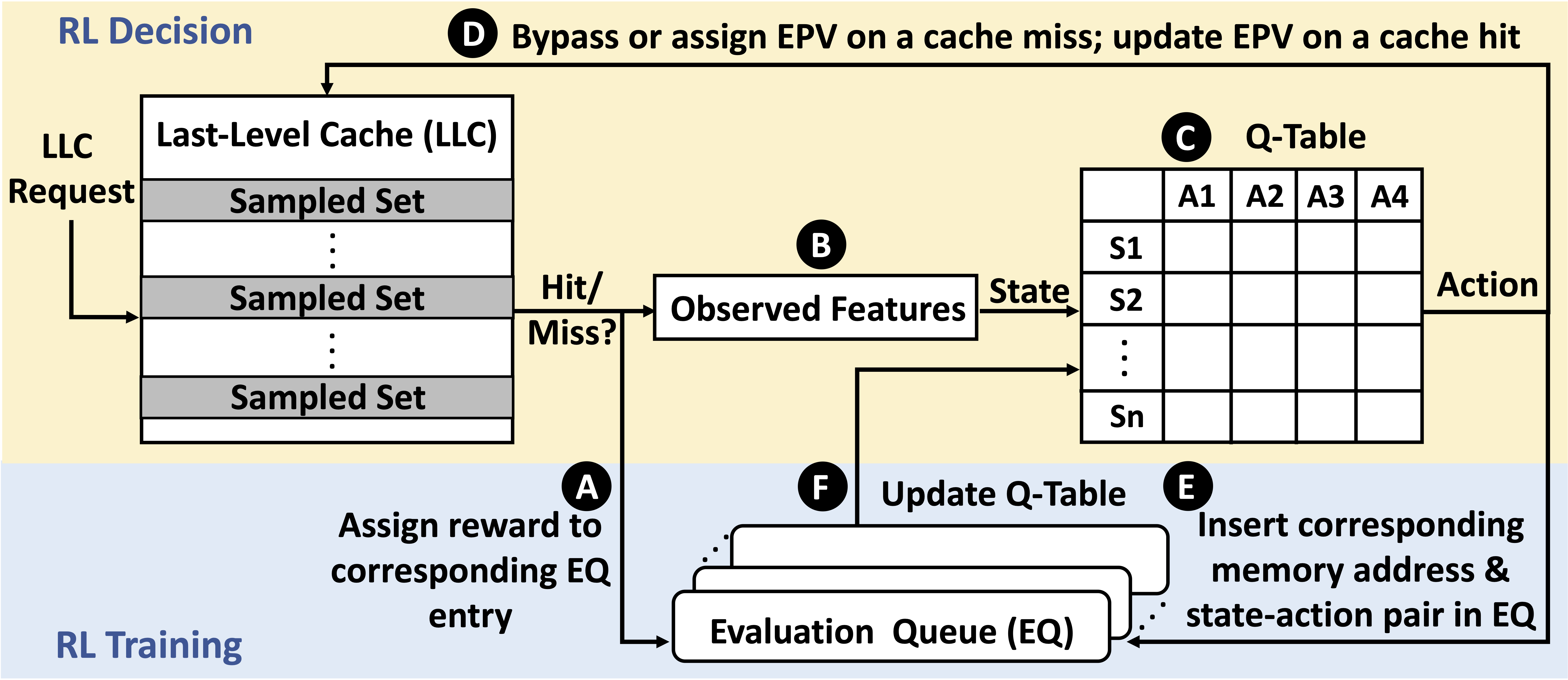
The Overview of the CHROME Design.
Project Significance
The Optimization of Memory Architectures project addresses critical challenges in modern memory architecture, providing both theoretical and practical advances in memory performance modeling. By considering data locality and concurrency, this research establishes a foundation for scalable, high-performance computing architectures. These advancements equip future systems to efficiently support the most demanding data-intensive applications, paving the way for breakthroughs in computer architecture, high-performance computing, and beyond.
Publications
Authors | Title | Venue | Type | Date | Links |
|---|---|---|---|---|---|
| , , , | CHROME: Concurrency-Aware Holistic Cache Management Framework with Online Reinforcement Learning | The 30th IEEE International Symposium on High-Performance Computer Architecture (HPCA 2024), Edinburgh, Scotland | Conference | March, 2024 | |
| , , | CARE: A Concurrency-Aware Enhanced Lightweight Cache Management Framework | The 29th IEEE International Symposium on High-Performance Computer Architecture (HPCA-29), Montreal, QC, Canada, February 25 - March 01, 2023 | Conference | February, 2023 | |
| , | The Memory-Bounded Speedup Model and Its Impacts in Computing | Journal of Computer Science and Technology (JCST'23), vol. 38, no. 1, February 2023 | Journal | February, 2023 | |
| , , , | A Generalized Model For Modern Hierarchical Memory System | The 2022 Winter Simulation Conference (WSC), Singapore, December 11-14, 2022 | Conference | December, 2022 | |
| , , | Premier: A Concurrency-Aware Pseudo-Partitioning Framework for Shared Last-Level Cache | The 2021 IEEE 39th International Conference on Computer Design (ICCD'21), October 24 - 27, 2021 | Conference | October, 2021 | |
| , , | A Study on Modeling and Optimization of Memory Systems | Journal of Computer Science and Technology (JCST'21), vol. 35, no. 1, January 2021 | Journal | January, 2021 | |
| , , | APAC: An Accurate and Adaptive Prefetch Framework with Concurrent Memory Access Analysis | The 38th IEEE International Conference on Computer Design (ICCD'20), October 18 - 21, 2020 | Conference | October, 2020 |
Sponsor

This research is supported by the National Science Foundation under Grant CCF-2008907.