UniMCC: Towards A Unified Memory-centric Computing System with Cross-layer Support
Background
As data volumes grow exponentially, traditional memory systems are being restructured to meet the demands of data-centric applications. From distributed machine learning to irregular graph mining, these applications require substantial data storage and computation while producing significant intermediate data that must be moved across compute resources. Consequently, memory has become a primary bottleneck in high-performance computing.
UniMCC (Unified Memory-centric Computing) seeks to address this challenge by developing a Unified Memory-centric Computing System through a cross-layer, full-stack approach. This project spans architecture, software/hardware interfaces, code generation, runtime support, and performance modeling. By addressing memory performance holistically, UniMCC provides a scalable and efficient framework for data-intensive applications, advancing the field of memory-centric computing.
Current Progress
CHROME: Concurrency-Aware Holistic Cache Management
- Overview: CHROME is an innovative cache management framework that leverages concurrency-aware, online reinforcement learning to optimize cache performance in dynamic environments.
- Adaptive Learning: By continuously interacting with the processor and memory system, CHROME learns and adapts its cache management policy in real-time. This online reinforcement learning approach enables CHROME to perform effectively across diverse system configurations and fluctuating workloads.
- Decision-Making: CHROME makes bypassing and replacement decisions based on multiple program features and system-level feedback, considering concurrency to enhance overall cache efficiency.
- Performance: Extensive evaluations show that CHROME consistently outperforms traditional cache management schemes, achieving a 13.7% performance improvement in 16-core systems, proving its potential for improving cache performance in data-intensive, scalable computing systems.
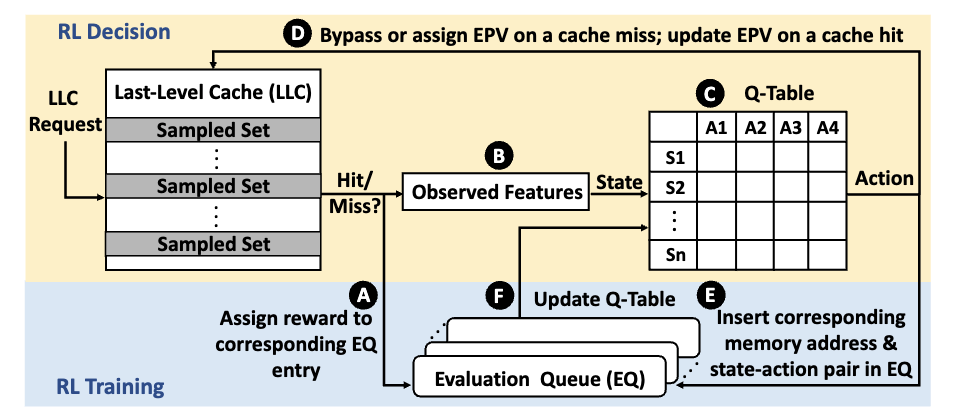
The Overview of the CHROME Design.
ACES: Adaptive and Concurrency-Aware Sparse Matrix Accelerator
- Overview: The ACES accelerator provides a novel combination of adaptive execution flows and concurrency-aware memory optimizations specifically designed for sparse matrix-matrix multiplication.
- Adaptive Execution Flow: ACES features an adaptive execution flow that can intelligently balance data reuse and synchronization across sparse data patterns, enhancing performance by selecting the optimal execution strategy for each unique workload.
- Concurrency-Aware Cache Management: By incorporating concurrency-aware cache optimizations and a non-blocking buffer, ACES minimizes data access stalls and improves cache efficiency, allowing it to handle irregular, large-scale sparse matrices with high concurrency.
- Performance: ACES demonstrates substantial improvements over existing accelerators, achieving up to a 2.1× speedup across various workloads, making it a powerful solution for accelerating data-intensive applications reliant on sparse data.
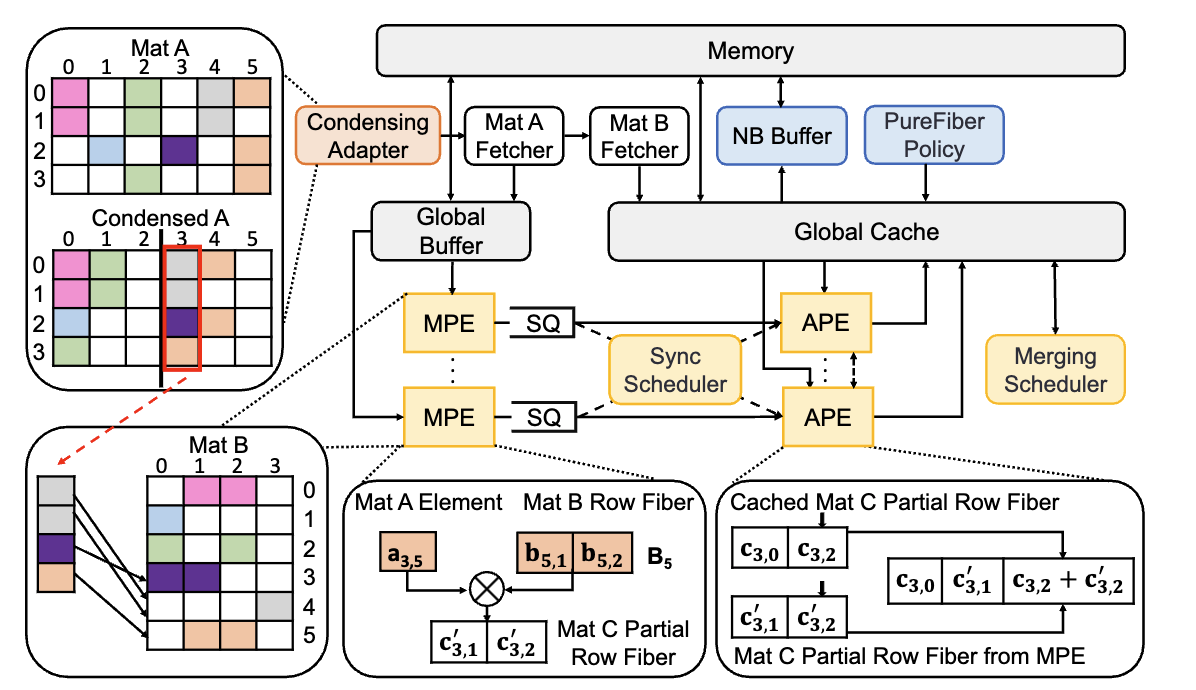
The Overview of the ACES Accelerator Design.
TrackFM: Compiler-Based Far Memory System
- Overview: TrackFM is a compiler-based far memory management system that provides programmer transparency and high performance by automatically transforming unmodified applications for efficient remote memory usage.
- Automatic Transformation: TrackFM uses LLVM-based compiler passes to inject guards and optimize memory access, enabling seamless integration with the AIFM runtime for fine-grained far memory management.
- Guard Optimization: Compiler-injected fast-path and loop chunking optimizations reduce redundant memory checks, ensuring efficient remote data access.
- Performance: TrackFM achieves up to a 12× speedup over Fastswap for workloads with small object sizes and low spatial locality and reduces redundant guard overheads, providing a 2.5× speedup in high-locality workloads.
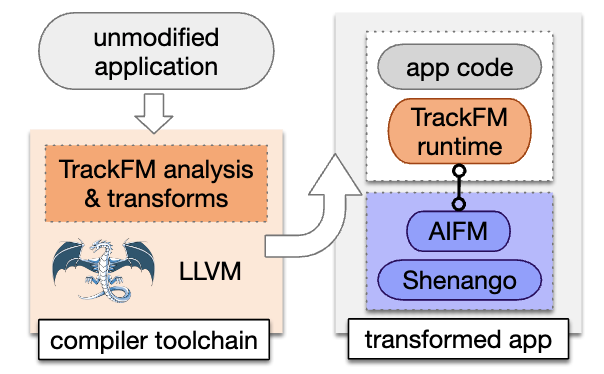
Users Compile Applications with TrackFM to Run on a Far Memory Cluster.
An Efficient Code Generator for KGE Score Functions
- Overview: This work presents a domain-specific compiler that generates optimized CUDA code for Knowledge Graph Embedding (KGE) score functions, addressing inefficiencies in existing tensor computation frameworks.
- Operator Fusion: It extends tensor compilers with batch operators tailored for scalar-vector, vector-vector, and matrix-vector operations, enabling efficient operator fusion, and reducing memory overhead.
- Runtime Optimization: The compiler employs runtime inspection to cache unique data indices in shared memory, minimizing global memory access and enhancing data reuse.
- Performance: The solution achieves a 14.9× speedup over TorchScript and 7.8× over TVM, with up to 3.6× faster execution compared to hand-optimized CUDA code. It improves end-to-end KGE training by 1.3× to 2.3× over PyTorch implementations.
Publications
-
Lu, Xiaoyang; Najafi, Hamed; Liu, Jason; Sun, Xian-He. "CHROME: Concurrency-Aware Holistic Cache Management Framework with Online Reinforcement Learning" 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). (https://doi.org/10.1109/HPCA57654.2024.00090)
-
Lu, Xiaoyang; Long, Boyu; Chen, Xiaoming; Han, Yinhe; Sun, Xian-He. "ACES: Accelerating Sparse Matrix Multiplication with Adaptive Execution Flow and Concurrency-Aware Cache Optimizations" Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. (https://doi.org/10.1145/3620666.3651381)
-
Tauro, Brian R.; Suchy, Brian; Campanoni, Simone; Dinda, Peter; Hale, Kyle C. "TrackFM: Far-out Compiler Support for a Far Memory World" Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. (https://doi.org/10.1145/3617232.3624856)
-
Hu, Lihan; Li, Jing; Jiang, Peng. "cuKE: An Efficient Code Generator for Score Function Computation in Knowledge Graph Embedding" 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). (https://doi.org/10.1109/IPDPS57955.2024.00085)
Sponsor

This research is supported by the National Science Foundation under Grant CNS-2310422.