![]()
Viper: A High-Performance I/O Framework for Transparently Updating, Storing, and Transferring Deep Neural Network Models
Overview
Scientific workflows are increasingly using Deep Learning (DL), requiring a Deep Neural Network (DNN) model to be trained and used for inferences at the same time. A common approach is for the training server (producer) and the inference server (consumer) to use separate model replicas that are kept synchronized. This setup, however, creates two major challenges:
-
Trade-off between Updates and Performance: A frequent model update schedule can improve inference quality because the consumer uses a more up-to-date model, but it can also slow down the training process due to the overhead of creating and transferring checkpoints. Conversely, infrequent updates may lead to less precise inference results.
-
Inefficient Model Transfer: Traditional methods for sharing models between the producer and consumer often rely on an intermediate staging area (e.g., PFS), causing significant delays due to I/O bottlenecks and the use of fixed-interval polling by the consumer to detect new models.
Key Contributions
Viper is high-performance I/O framework designed to both determine a near-optimal checkpoint schedule and accelerate the delivery of model updates. It is built on two core innovations:
-
Inference Performance Predictor (IPP): Identifies a near-optimal checkpoint schedule to effectively balance the trade-off between training slowdown and inference quality improvement.
-
Memory-first Model Transfer Engine: Accelerates model delivery by using direct memory-to-memory communication, bypassing slower storage like PFS. It prioritizes GPU-to-GPU memory transfer when available, falling back to host-to-host RDMA transfer if needed. This asynchronous engine, combined with a push-based notification module, ensures that consumers are promptly notified of new model updates without relying on polling.
Background
In traditional DL workflow, producer (Scientific AI Application) typically trains a DNN model offline with a fixed set of input data and then persists the trained model to a model repository for future use, while consumer (Inference Serving System) will load the pre-trained DNN model from the model repository and offers online inference queries for end-user applications.
However, this offline training is not an ideal choice in two scenarios:
- Scenario 1: Modern scientific DL workflows often operate in dynamic environments where new data is constantly changing and accumulating over time.
- To adapt to data changes, continuous learning is utilized to continuously (re)-train a DNN model by using some online techniques.
- Continuous learning implies the continuous deployment of the DNN model to keep the model up-to-date
- Scenario 2: The consumer may have a limited time window for inferences, it may need to start inferencing after the warmup phase in model training on the producer side
- Producer continues training the model while the consumer conducts inferences
- This requires the intermediate DNN models to be consistently delivered from the producer to the consumer during training to achieve high inference performance
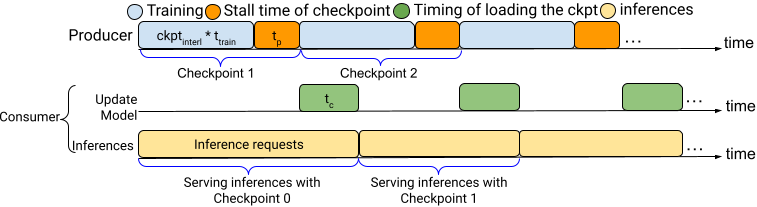
Both scenarios increase the model update frequency between producers and consumers.
Motivation
- Model update frequency affects both training and inference performance, since a model update operation involves both model checkpointing and model data delivery.E.g.,
- Frequent model updates can enhance inference performance but may slow down training
- Infrequent model updates may pose less overhead on training but may degrade the overall inference model accuracy
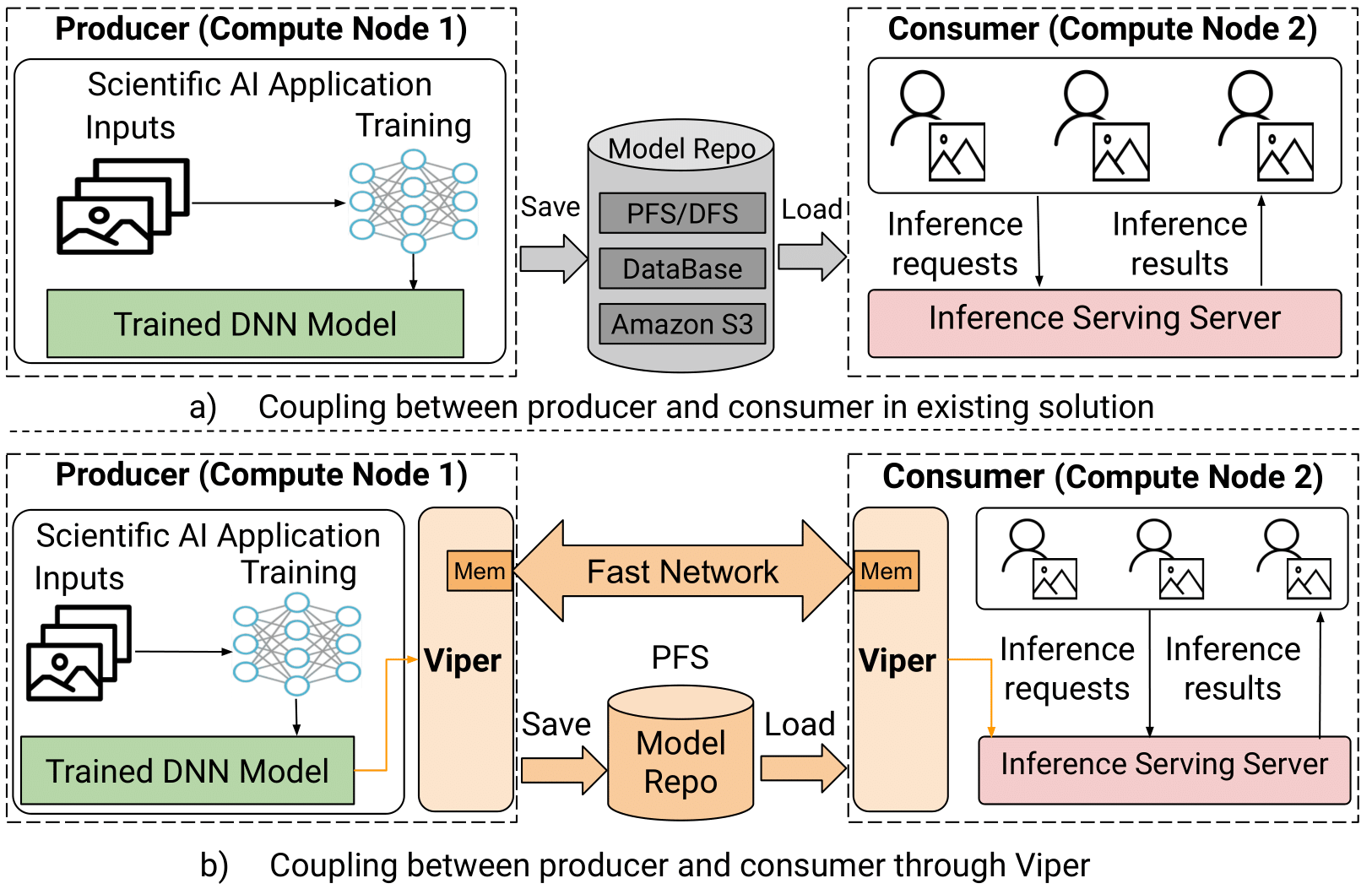
- Currently, Scientific AI Applications and Inference Serving Systems communicate through a model repository (e.g., PFS), as depicted in Figure (a). This communication method may result in:
- High model update latency due to the I/O bottlenecks caused by concurrent, uncoordinated, small I/O accesses to PFS
- High model discovery High model discovery latency on consumers due to the static fixed-interval pull-based (e.g., polling) detection mechanism
Thus, there is a need to 1) balance the trade-off between training and inference performance; 2) accelerate model data discovery and delivery between producers and consumers (Figure b).
Approach
Viper's High-level Architecture
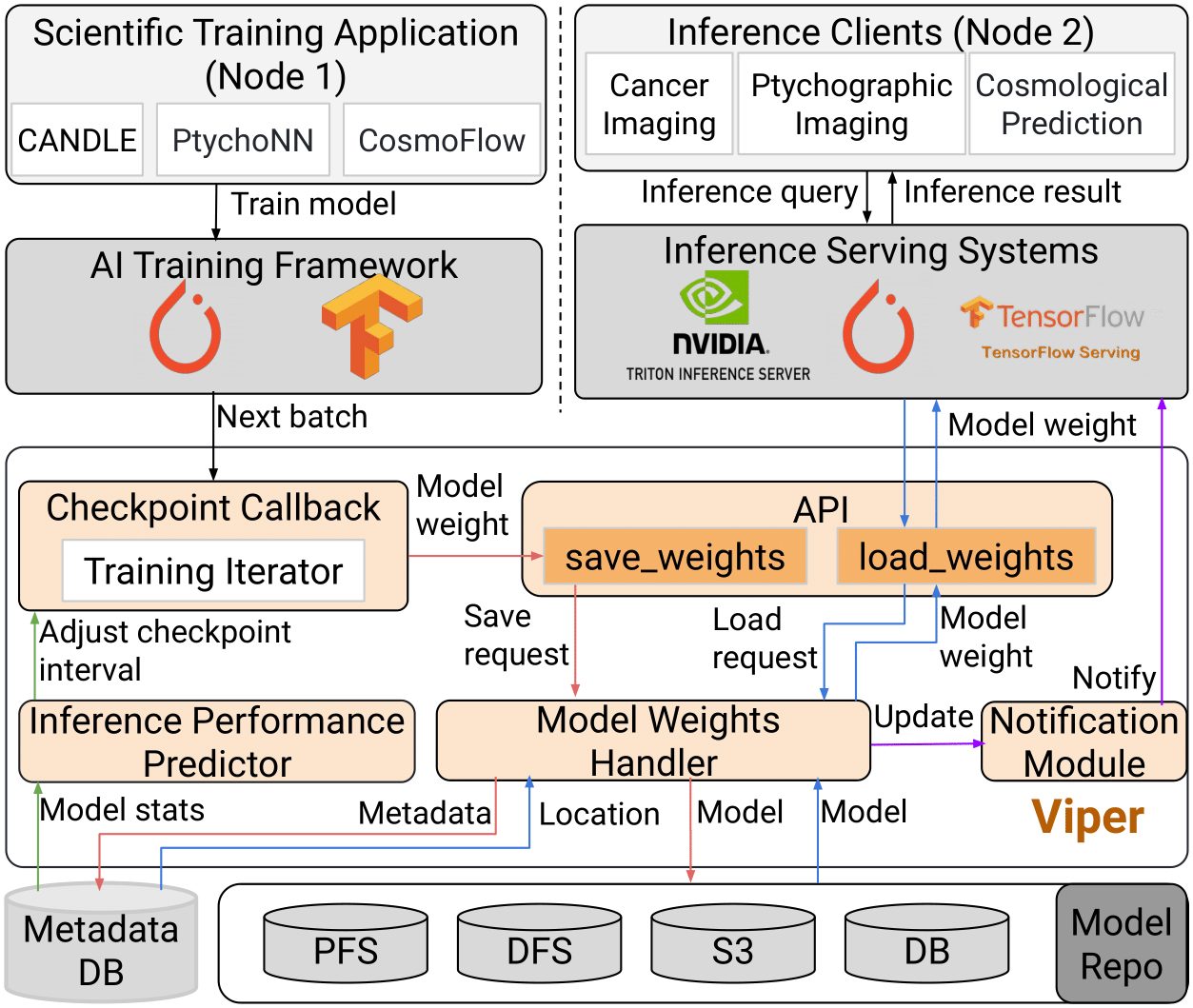
Viper is a high-performance I/O framework to accelerate DNN models exchange between producers and consumers. It aims to:
- Balance the trade-off between training runtime and inference performance
- Viper builds an intelligent inference performance predictor to achieve this object
- Can decide an optimal model checkpoint schedule between producers and consumers
- Supporting two different algorithms for finding the optimal checkpoint schedule
- Viper builds an intelligent inference performance predictor to achieve this object
- Accelerate model data transfer
- Viper creates a novel cache-aware data transfer engine to speedup model update between producers and consumers
- Creating a direct data exchange channel for model delivery and utilizes. E.g., the direct GPU-to-GPU or RAM-to-RAM data transfer strategy
- Utilizing a lightweight publish-subscribe notification mechanism to promptly inform the consumer of the model changes.
- Viper creates a novel cache-aware data transfer engine to speedup model update between producers and consumers
Accelerate Model Data Transfer
![]()
During training, DNN models can be cached on multiple alternative locations (e.g., GPU memory, Host memory, and PFS)
- Asynchronous memory-first engine
- Utilize the cached models on different locations to accelerate data movement between producer and consumer
- Creates a direct communication channel to transfer the model data
- Direct GPU-to-GPU memory and host-to-host memory data transfer strategy
- Implemented based on MPI library
- A lightweight publish-subscribe notification module to proactively inform consumers of model updates instead of passively periodic queries
Experiment Results
End-to-end Model Update Latency
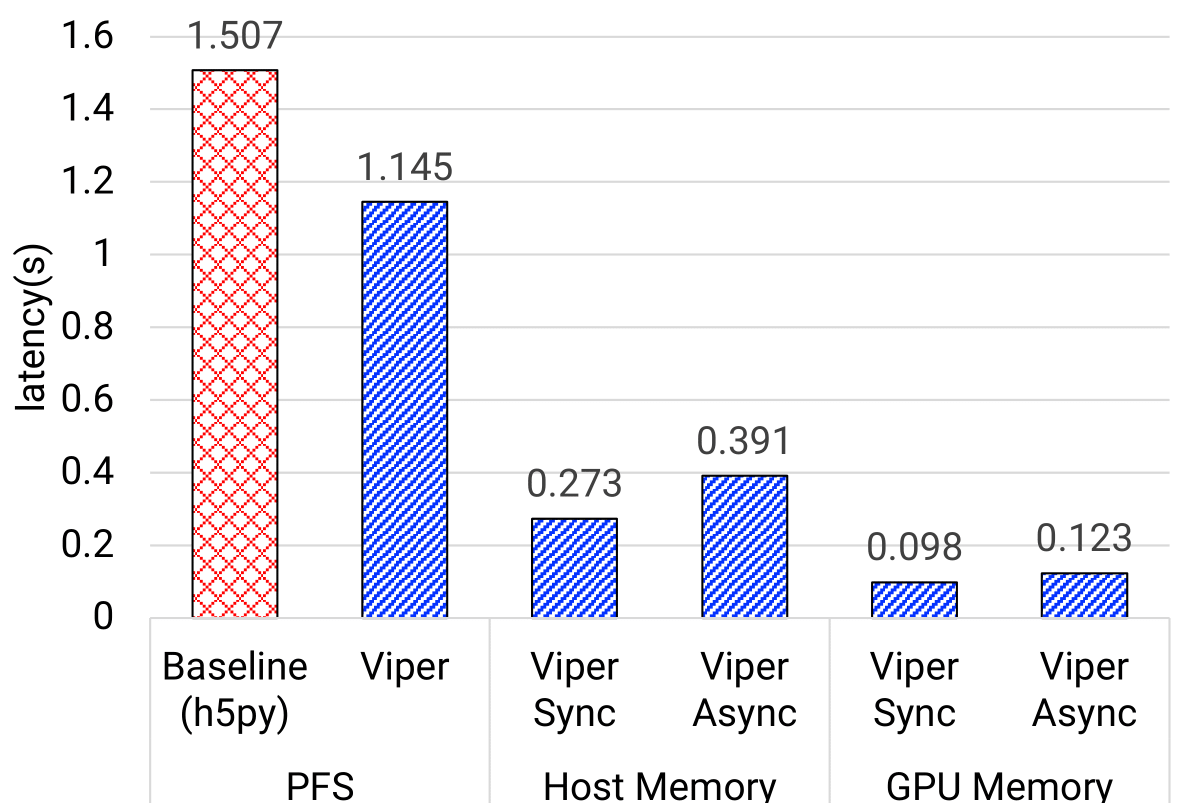
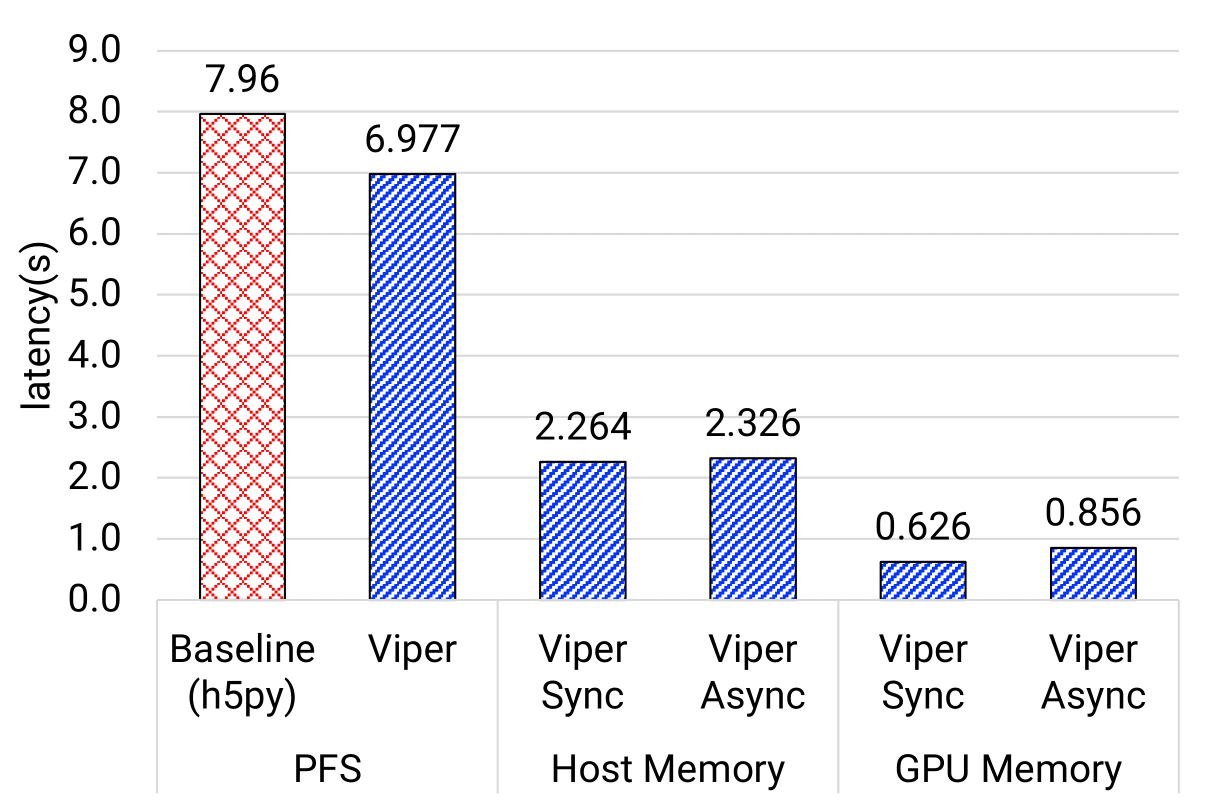
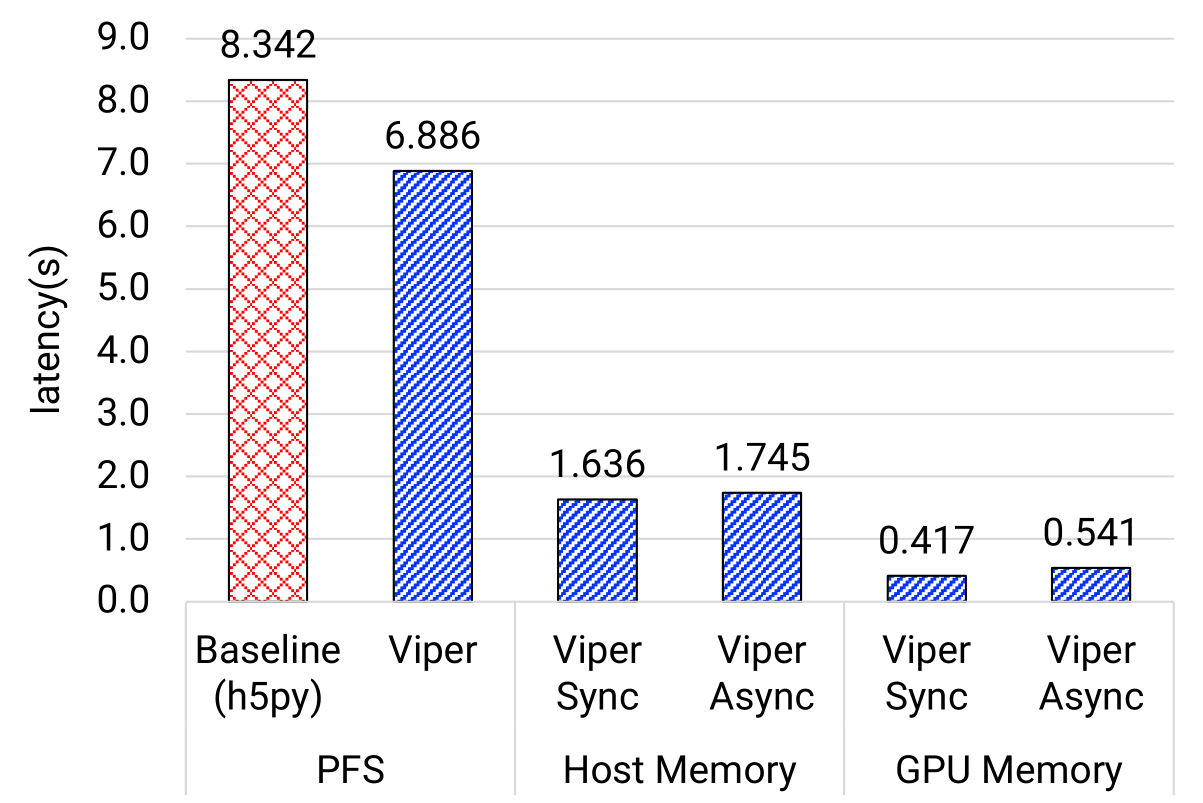
Goal: showcase the end-to-end model update latency across different model transfer strategies
Observations:
- Both GPU-to-GPU and Host-to-Host memory strategies achieve better performance than PFS
- GPU-to-GPU outperforms the baseline by 12x for NT3, 9x for TC1, and 15x for PtychoNN using Viper-Async approach
- Host-to-Host using Viper-Async approach is at least 3x better than baseline
- This is attributed to high I/O bandwidth of the fast memory tiers and the high-speed network
- Viper-PFS approach is also ~1.2x faster than baseline since it only writes model weights and closely related metadata into the file
- Viper-Async is slower than Viper-sync because it uses a separate thread for data transfer to reduce training interruption, requiring an extra data copy
Inference Performance Predictor
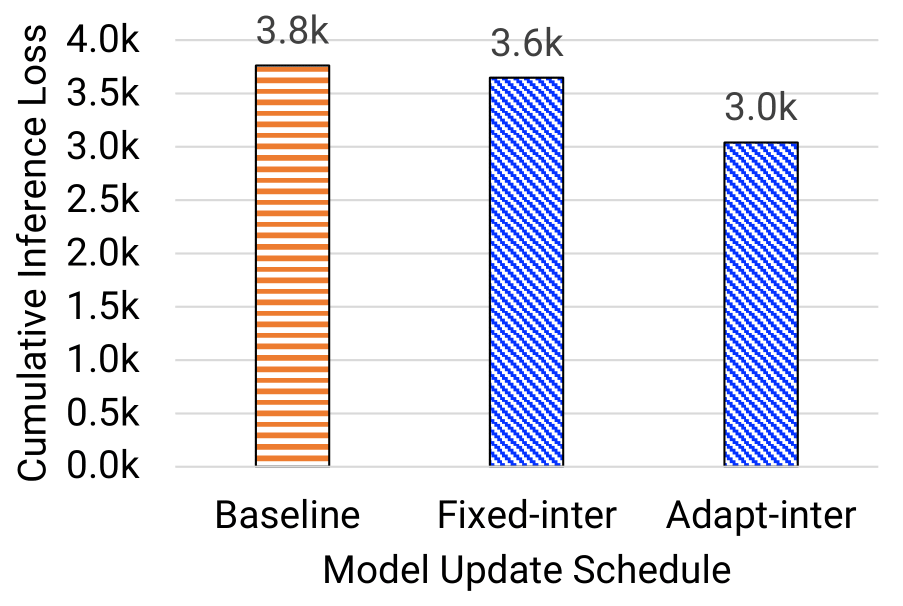
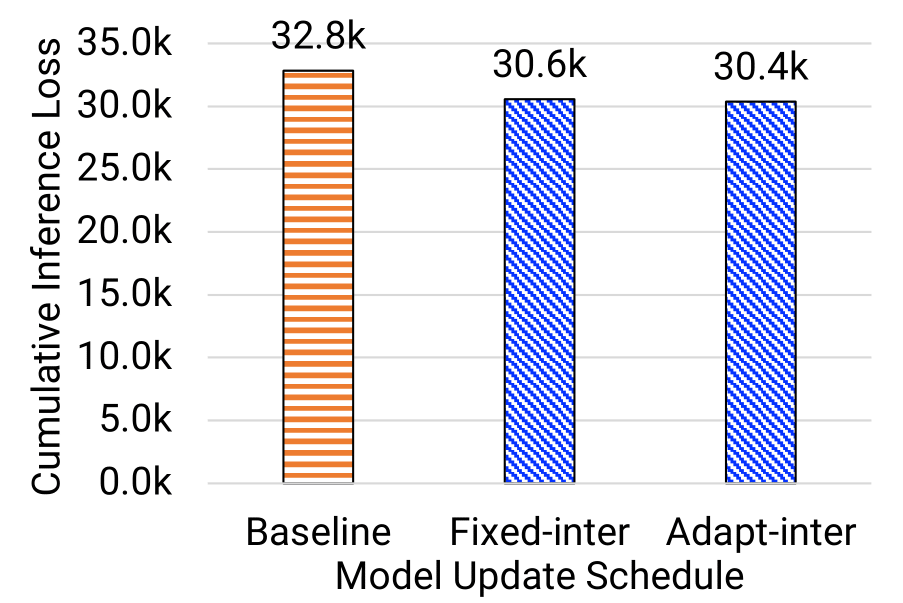
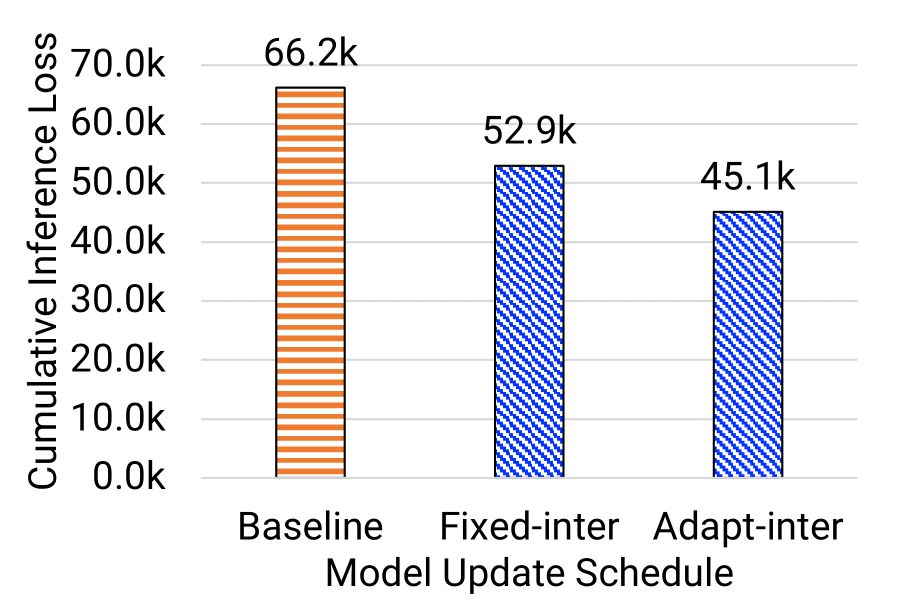
Goal: showcase the checkpoint schedule identified by the Inference Performance Predictor (IPP) can achieve lower CIL compared to baseline
Observations:
- Both fixed-interval and adaptive-interval checkpoint schedule can achieve better CIL compared with the baseline (i.e., epoch-boundary checkpoint schedule)
- Adaptive-interval checkpoint schedule is better than fixed-interval approach
- For NT3 model, adaptive-interval schedule reduces the CIL from 3.8k to 3.0k
- For TC1 model, adaptive-interval schedule reduces the CIL from the 32.8k to 30.4k
- For PtychoNN model, adaptive-interval schedule reduce the CIL from the baseline of 66.2k to 4.0k
Members
- Jie Ye, Illinois Institute of Technology
- Jaime Cernuda, Illinois Institute of Technology
- Bogdan Nicolae, Argonne National Laboratory
- Anthony Kougkas, Illinois Institute of Technology
- Xian-He Sun, Illinois Institute of Technology